正则使用手册
Posted on Wed, 17 Sep 2025 10:44:30 +0800 by LiangMingJian
概述
正则表达式(Regular Expression,简称 Regex 或 RegExp)是一种用来匹配字符串中字符的工具。它可以帮助开发者完成诸如查找、替换、验证、提取等工作。
构建正则表达式的方法和创建数学表达式的方法一样,通过结合原义字符和元字符来达成想要的匹配逻辑。
原义字符是指待匹配字符串中原有的字符,主要用于匹配的定位。
元字符是具有特殊含义的字符,它不表示字面意义,只用于控制匹配模式。
比如对于字符串 Hello World,有正则表达式 W.*,匹配结果为 World。在这里,W 就是原义字符,.* 就是元字符。
.*的功能是匹配零次或多次除换行符(\n、\r)之外的任何单个字符。
正则的过程
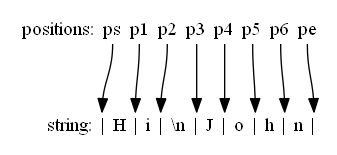
正则的匹配是逐位置匹配,在匹配开始时,会将一个光标移动至首字符前位置,然后从首字符前逐个开始匹配,当匹配到目标字符后,存储该目标字符,然后移动光标到下一个位置继续匹配,判断该下个字符是不是所需的内容,以此往复,直到结束。
一个 N 长度的字符会有 N+1 个位置,位置不会占用内存,仅用于匹配定位。
元字符
元字符是正则中具有特殊含义的字符,它不用于表示字义,用于提供各种匹配模式的使用。
基本元字符
基本元字符主要用于匹配符合一定规律的单个字符,比如数字,大写字母,小写字母等。
目标字符串:ab _.12。
| 基本元字符 | 描述 | 示例 |
|---|---|---|
. | 匹配除换行符 \n 外任意单个字符 | a, b, 空格, _, ., 1, 2 |
\d | 匹配任意的单个数字字符 | 1, 2 |
\D | 匹配任意的单个非数字字符 | a, b, 空格, _, ., |
\w | 匹配任意的单个字母,数字,下划线字符 | a, b, _, 1, 2 |
\W | 匹配任意的单个非字母,数字,下划线字符 | 空格, . |
\s | 匹配任意的单个空白字符 | 空格 |
\S | 匹配任意的单个非空白字符 | a, b, _, ., 1, 2 |
位置元字符
位置元字符主要用于限定匹配的位置,不占用字符空间。
目标字符串:ab12ab12.12
| 位置元字符 | 描述 | 示例 |
|---|---|---|
^ | 匹配开头 | ^ab,匹配字符串开头的 ab |
$ | 匹配结尾 | 12$,匹配字符串结尾的 12 |
\b | 限定匹配的边界是非字母、数字、下划线 | \b12\b,将匹配 .12 中的 12 |
\B | 限定匹配的边界是字母、数字、下划线 | \B12\B,将匹配 ab12ab 中的 12 |
集合元字符
集合元字符主要用于匹配给定范围内的任意字符。
目标字符串:abcde123456
| 集合元字符 | 描述 | 示例 |
|---|---|---|
[] | 定义字符集合,匹配其中的任意一个字符 | [abc],匹配 a, b, c |
[^] | 定义字符集合,匹配非其中的任意一个字符 | [^de123456],匹配 a, b, c |
- | 在字符集合内用于表示范围 | [a-z],a 到 z 所有字符,匹配 a, b, c, d, e |
量词元字符
量词元字符主要用于限定匹配的次数。量词字符串的匹配是从位置开始的,因此其匹配结果可能会出现位置,同时会将符合量词次数的字符合并返回。
目标字符串:01123456789。
| 量词元字符 | 描述 | 示例 |
|---|---|---|
* | 要求前面的表达式出现 0 次或多次 | 1*,匹配字符 11 (2次)和其他 10 个位置(0次) |
+ | 要求前面的表达式出现 1 次或多次 | 1+,匹配字符 11 (2次) |
? | 要求前面的表达式出现 0 次或 1 次 | 1?,匹配字符 1 (1次)和 1(1次)和其他 10 个位置(0次) |
{n} | 要求前面的表达式出现 n 次 | 1{2},匹配字符 11 (2次) |
{n,} | 要求前面的表达式至少出现 n 次 | 1{1,},匹配字符 11 (2次) |
{n,m} | 要求前面的表达式出现 n 次到 n 次 | 1{1,2},匹配字符 11 (2次) |
特殊的,量词元字符默认都是贪婪量词,在匹配时尽可能的匹配。支持通过在量词元字符后面添加 ?,使其变成非贪婪量词,尽可能少的匹配,如 *?, +?, ?? 等*。
非贪婪量词会在匹配时尽可能少的进行匹配,比如 1+? 会直接匹配到两个字符 1(1次),而不是像贪婪量词一样匹配到一个字符 11(2次)。
分组元字符
分组元字符主要用于定义组,使用该元字符的正则会按组匹配内容。
目标字符串:ababc。
| 分组元字符 | 描述 | 示例 |
|---|---|---|
() | 按包括内容进行匹配 | (ab)+,按 ab 匹配 1 次或多次,匹配结果 abab |
选择元字符
选择元字符用于为正则提供“或”功能。
目标字符串:ababc。
| 选择元字符 | 描述 | 示例 |
|---|---|---|
| | | 提供或运算 | a|c,匹配 a 或 c,匹配结果 a, a, c |
特殊元字符
特殊元字符主要用于匹配换行符,制表符,回车符等这类转义字符。
| 特殊元字符 | 描述 |
|---|---|
| \ | 转义字符,使元字符失去功能,比如 \. 就是普通点号 |
| \n | 匹配换行符 |
| \t | 匹配制表符 |
| \r | 匹配回车符 |
| \f | 匹配换页符 |
| \v | 匹配垂直制表符 |
预查元字符
预查元字符用来对匹配字符前后是否符合一定规则进行检查,预查元字符中的匹配内容不会实际获取,也不会存储,不影响原有字符的匹配。
目标字符串:Windows11,Windows7。
| 预查元字符 | 描述 | 示例 |
|---|---|---|
| (?:pattern) | 满足预查内容的字符会被匹配到,结果包括预查字符 | Windows(?:11|10),可以匹配 Windows11 但不能匹配 Windows7 |
| (?=pattern) | 满足预查内容的字符会被匹配到,结果不包括预查字符 | Windows(?=11|10),可以匹配 Windows11 中的 Windows |
| (?!pattern) | 不满足预查内容的字符会被匹配到,结果不包括预查字符 | Windows(?!11|10),可以匹配 Windows7 中的 Windows |
| (?<=pattern) | 反向预查,和上述正向匹配位置相反 | (?<=11|10)Windows,可以匹配 10Windows 中的 Windows |
| (?<!pattern) | 反向预查,和上述正向匹配位置相反 | (?<!11|10)Windows,可以匹配 7Windows 中的 Windows |
修饰符
修饰符是用来改变正则表达式匹配行为的特殊字符,与元字符是完全不同的两个东西。
修饰符需要使用在正则表达是外面,即 /pattern/flags,使用斜杆包裹正则表达式,然后在表达式最后面的添加修饰符 flags。
特别注意,修饰符在不同计算机编程语言中的支持程度不同,请注意辨别使用。
| 修饰符 | 描述 | 支持 |
|---|---|---|
| i | 不区分大小写 | 基本都支持 |
| g | 全局匹配,不只匹配一个 | Python 不支持 |
| m | 多行匹配,使 ^ 和 $ 匹配每行的开头和结尾,而不是字符串首位 | 基本上都支持 |
| s | 全匹配,使 . 匹配包括换行符在内所有字符 | 基本上都支持 |
| u | 启用 Unicode 支持,可以匹配 Unicode 字符 | 基本上都支持 |
| y | 粘性匹配,从尾部开始匹配 | 只有 JavaScript 支持 |
| x | 扩展模式,忽略表达式中的空白和注释 | JavaScript 不支持 |
常用的正则示例
- 至少长度 1 的中文汉字:
^[\u4e00-\u9fa5]+$ - 至少长度 1 的英文和数字:
^[A-Za-z0-9]+$ - 邮箱:
^\w+([-+.']\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ - 域名:
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.? - 手机号码:
^(13[0-9]|14[01456879]|15[0-35-9]|16[2567]|17[0-8]|18[0-9]|19[0-35-9])\d{8}$ - 身份证:
(^\d{15}$)|(^\d{18}$)|(^\d{17}[\dXx]$) - IPv4 地址:
((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}
————————————