如何在 Selenium 中进行等待
Posted on Wed, 25 Dec 2024 16:13:32 +0800 by LiangMingJian
概述
在 Selenium 自动化测试中,由于网页加载速度与代码执行速度的差异,如果代码在网页没准备好时便直接操作元素,此时脚本的操作可能会失败。
因此等待机制是确保脚本稳定运行的关键,Selenium 提供三种主要的等待方式:强制等待、隐式等待和显式等待。
强制等待
通过标准库 time 的 sleep() 方法直接使代码停止执行。
from selenium import webdriver
import time
service = webdriver.ChromeService(r"F:\Sdk\webdriver\chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.maximize_window()
driver.get("https://www.baidu.com")
# 强制等待,以保证网页全部加载完成
time.sleep(3)
driver.quit()
隐式等待
Selenium 自身提供两种等待机制:隐式等待和显式等待。
隐式等待通过 driver.implicitly_wait() 设置了一个全局等待时间,它要求代码如果在规定等待时间内找到目标元素就执行下一步,如果没有找到则报错。
需要注意的是,隐式等待在设置一次后,就会对所有元素生效。同时隐式等待默认要求代码需要等待全部元素加载完毕,才能执行下一步,这也是它的缺点。
import time
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.common.by import By
service = webdriver.ChromeService(r"F:\Sdk\webdriver\chromedriver.exe")
driver = webdriver.Chrome(service=service)
# 设置隐式等待时间
driver.implicitly_wait(10)
driver.maximize_window()
driver.get("https://www.baidu.com")
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 在 10s 内找到元素继续执行,找不到则报错
try:
driver.find_element(By.ID, "abc")
except NoSuchElementException:
print(NoSuchElementException)
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
driver.quit()
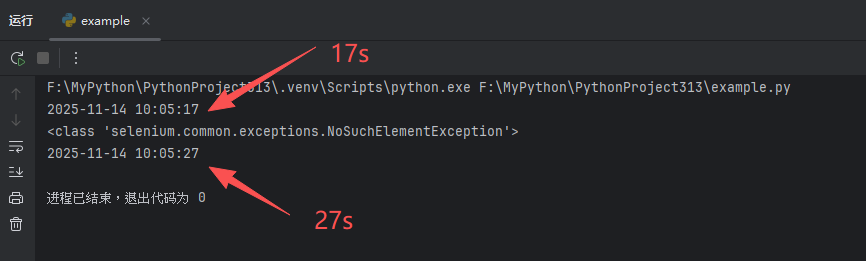
上面的代码执行结果如下,可以看见:即使无法找到元素,代码也会按隐式等待时间进行等待,在 10s 后才抛出错误。
如果没有设置隐式等待时间,代码在没有找到元素的一瞬间就会抛出错误。
显式等待
显式等待是 Selenium 提供的另外一种等待方式。
显式等待通过类 WebDriverWait 和断言工具 expected_conditions 要求代码每隔一段时间进行检查,检查中如果找到元素则执行下一步,否则抛出超时异常。
需要注意,显示等待不要求全部元素加载完毕,只要元素被找到,并符合断言工具的要求,则代码会直接进行下一步。
import time
from selenium import webdriver
from selenium.common import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
service = webdriver.ChromeService(r"F:\Sdk\webdriver\chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.maximize_window()
driver.get("https://www.baidu.com")
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 设置显式等待时间,要求 10s 内每 2s 检查一次元素是否存在
try:
element = WebDriverWait(driver, 10, 2).until(
EC.presence_of_element_located((By.ID, "abc")))
except TimeoutException:
print(TimeoutException)
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
driver.quit()
在上述代码中,expected_conditions 是 Selenium 提供的断言工具,通常我们在使用时可以用 EC 来进行简写替代,它提供了一系列预定义的条件方法来判断页面状态是否符合预期,比如针对元素状态,有:
presence_of_element_located():元素是否加载visibility_of_element_located():元素是否可见element_to_be_clickable():元素是否可点击
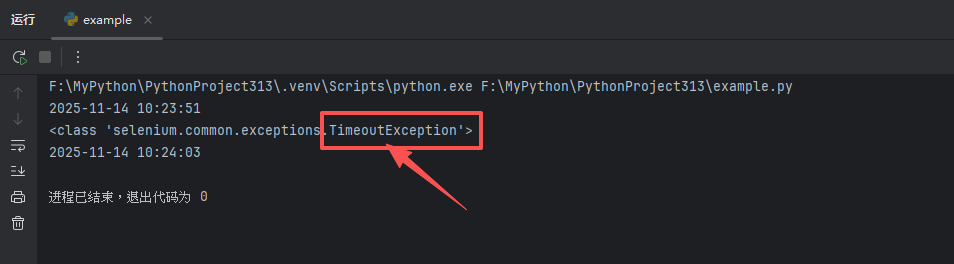
可以看到下面执行结果,同样等待了 10s,但报错信息变更为 TimeoutException。
拓展阅读:页面的加载状态
在 HTML 网页中,Web 网页的加载状态由页面属性 document.readyState 来进行描述。这个属性有三个值:loading(正在加载)、interactive(可交互)、complete(完成)。
默认情况下,在 document.readyState 变为 complete 前,Selenium WebDriver 会延迟 driver.get() 的响应或 driver.navigate().to() 的调用,即在网页加载完成前,不会进行任何自动化操作。
对于上述的机制,Selenium WebDriver 支持通过属性 page_load_strategy 来进行配置。这个属性有三种取值:normal(等待整个页面完全加载)、eager(等待整个页面加载,但不要求 CSS 和图片加载)、none(仅等待初始页面下载完成,不考虑 Javascript 执行后需要加载的内容)。
默认情况下,Selenium WebDriver 遵循 normal 的页面加载策略,始终加载所有内容。但在页面访问缓慢时,你可以使用 eager 模式,停止下载其他资源,以便更快速的开始自动化操作。
import time
from selenium import webdriver
service = webdriver.ChromeService(r"F:\Sdk\webdriver\chromedriver.exe")
options = webdriver.ChromeOptions()
# 设置页面加载方式
options.page_load_strategy = 'eager'
driver = webdriver.Chrome(service=service, options=options)
driver.maximize_window()
driver.get("https://www.baidu.com")
time.sleep(3)
driver.quit()
另外,Selenium WebDriver 还提供 set_page_load_timeout() 方法,支持开发者主动设置网页加载超时时间,在超时后手动结束页面加载,并执行后续代码。
from selenium import webdriver
service = webdriver.ChromeService(r"F:\Sdk\webdriver\chromedriver.exe")
driver = webdriver.Chrome(service=service)
# 设置 1s 超时时间
driver.set_page_load_timeout(1)
driver.maximize_window()
driver.get("https://www.baidu.com")
# 代码报 TimeoutException,1s 内没有完全加载
driver.quit()