如何隐藏 Selenium 自动化的痕迹
Posted on Wed, 25 Dec 2024 16:13:27 +0800 by LiangMingJian
需求
在使用 Selenium + Webdriver 执行自动化任务时,Selenium 往往会在浏览器的 Navigator 或 Document 对象里注入一些自动化特有的属性。
在某些严格限制的网页系统上,这些属性如果被网页检测到存在,那我们的行为就会被识别为机器人在访问,而无法正常获取内容。
打开 https://bot.sannysoft.com/ 这个网站,我们可以简单的查看浏览器属性,进而判断我们的行为是否会被识别为机器人。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r"F:\Sdk\webdriver\chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.maximize_window()
driver.get("https://bot.sannysoft.com/")
time.sleep(10)
driver.quit()
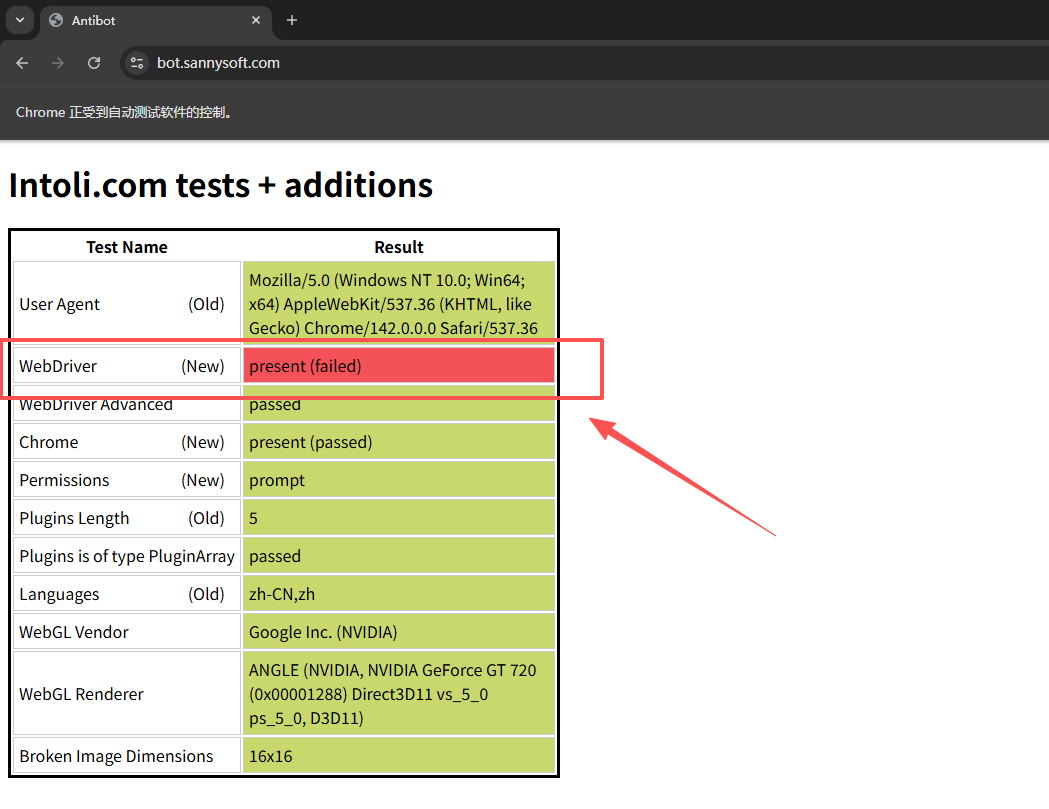
这是通过 Selenium 自动化时的属性:
这是没有自动化时的属性:
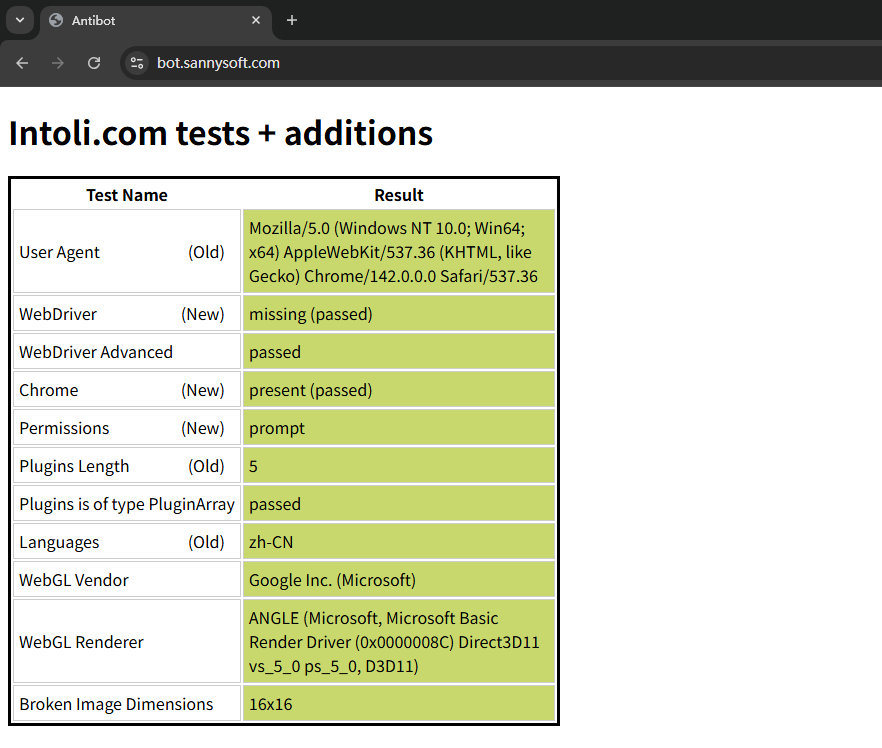
通过删除 navigator.webdriver 属性来进行隐藏
对于大部分的网页系统,其对于是否自动化的判断通常都是基于 navigator.webdriver 这个属性进行检测的。
在正常的浏览器中这个属性的值是 undefined 或者 false。但如果浏览器被 Selenium 之类的工具自动控制的话,这个值将会变为 true,因此这是个检查自动操作的好方法。
根据 MDN # Navigator: webdriver property 的描述,navigator.webdriver 是个只读属性,因此我们不可能对这个值重新赋值。
另外,即使重写这个属性的 getter(用于访问对象属性值的一个特殊方法),网页还是可以通过执行 navigator.hasOwnProperty('webdriver') 来进行检测。
// 重写 navigator.webdriver 的 getter
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined,
});
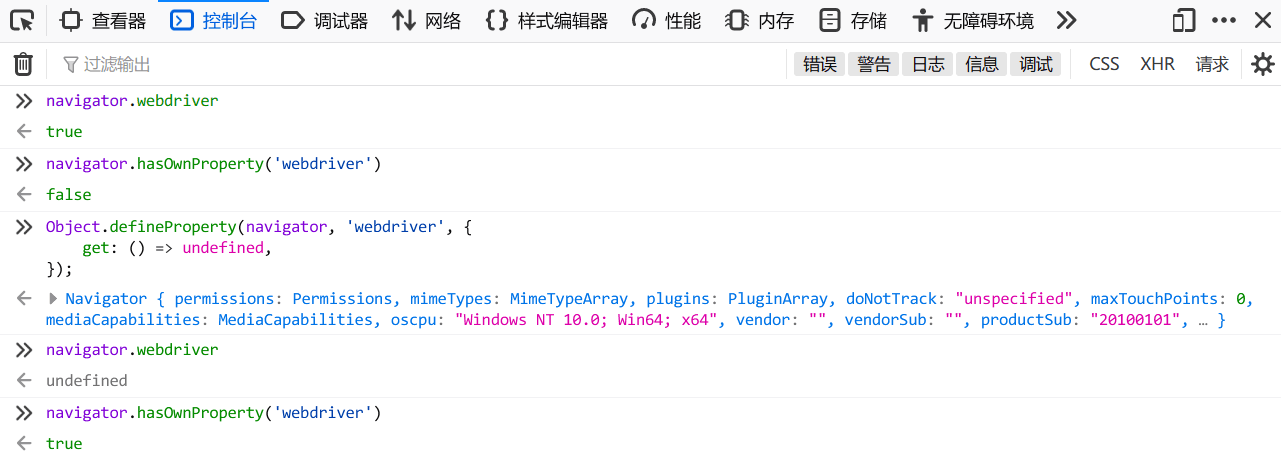
所以,解决这个问题最好的办法是在打开网页前把这个属性删除掉。
对于 Chrome 内核的浏览器
如果是 Chrome 内核的浏览器(Edeg 也是 Chrome 的),那么要删除这个属性,可以在浏览器的启动参数里添加 --disable-blink-features=AutomationControlled,然后在实验室选项中配置 enable-automation 并关闭 useAutomationExtension。
比如使用下述代码启动浏览器:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r"F:\Sdk\webdriver\chromedriver.exe")
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(service=service, options=options)
driver.maximize_window()
driver.get("https://bot.sannysoft.com/")
time.sleep(10)
driver.quit()
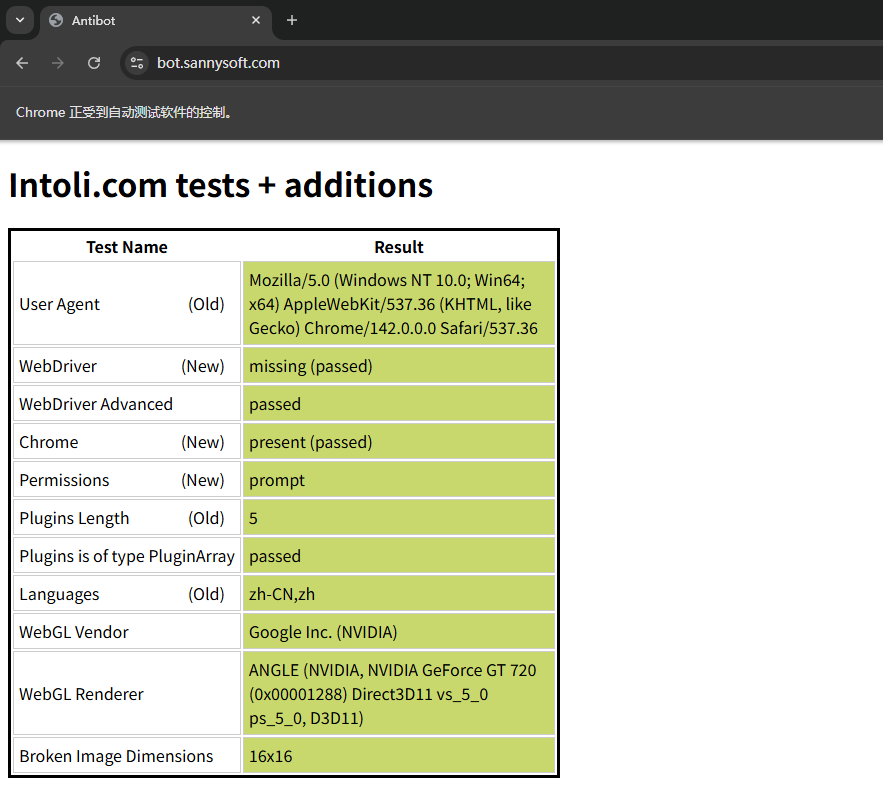
可以看到,上述代码在执行后,所有自动化控制的信息都消除了:
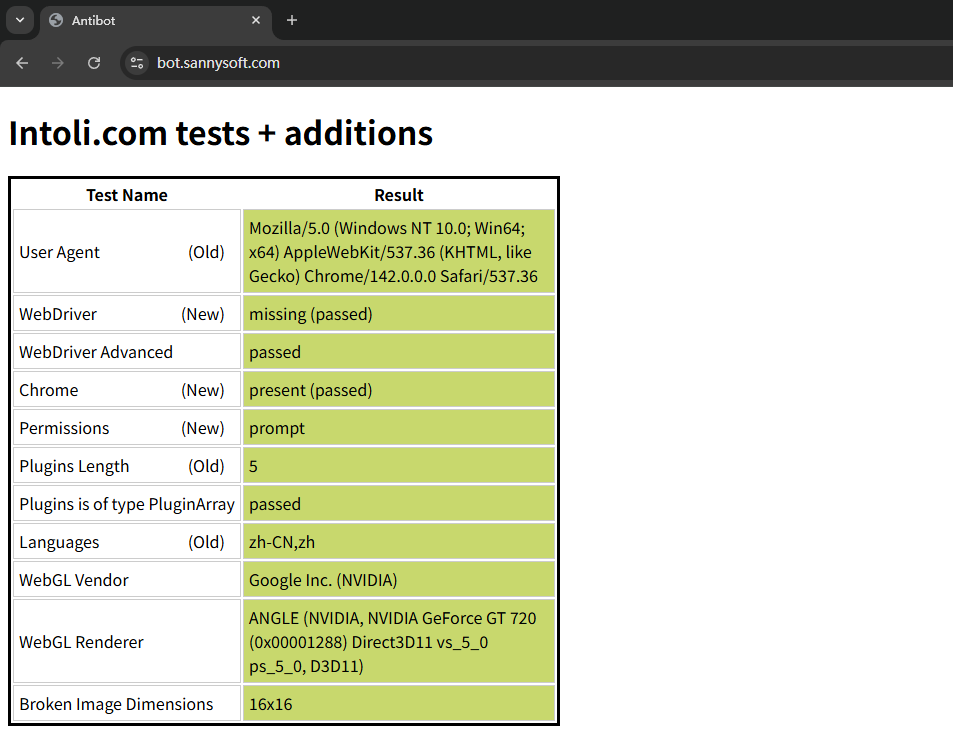
当然,除了通过上述配置启动项的方法外,还可以通过 execute_cdp_cmd() 方法,调用 Chrome DevTools Protocol CDP 开发者工具来让浏览器在打开网页前执行删除 navigator 属性的 JavaScript 代码。
下面的代码,也能实现上述消除自动化信息的效果:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r"F:\Sdk\webdriver\chromedriver.exe")
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=service, options=options)
driver.maximize_window()
driver.execute_cdp_cmd(
'Page.addScriptToEvaluateOnNewDocument',
{'source': 'delete navigator.__proto__.webdriver'})
driver.get("https://bot.sannysoft.com/")
time.sleep(10)
driver.quit()
此时,虽然浏览器还是有显示自动化控制,但网页上已经识别不到了。
对于 Firefox 浏览器
与 Chrome 浏览器不同,Firefox 浏览器没有这么多启动参数和实验项可以让我们消除自动化信息,因此我们只能在浏览器启动后通过 JavaScript 代码进行删除。
同上,因为 Firefox 没有 CDP 开发者工具,因此为了在打开网页前执行删除代码,我们需要使用扩展来实现这一需求。
创建扩展的元数据文件 manifest.json
{
"manifest_version": 2,
"name": "WebdriverCleaner",
"version": "1.0",
"description": "Clean navigator.webdriver",
"content_scripts": [
{
"run_at": "document_start",
"matches": ["*://*/*"],
"js": ["borderify.js"]
}
]
}
创建扩展的功能文件 borderify.js
delete window.navigator.wrappedJSObject.__proto__.webdriver;
console.log('finish:', window.navigator.wrappedJSObject.webdriver);
将上述两个文件压缩为 borderify.zip,并放在项目下,在启动浏览器时加载
特别注意,压缩的扩展 ZIP 文件必须是扩展文件本身的 ZIP 文件,而不是包含它们目录的 ZIP 文件。
from selenium import webdriver
import time
service = webdriver.FirefoxService(r"F:\Sdk\webdriver\geckodriver.exe")
driver = webdriver.Firefox(service=service)
# 加载扩展
driver.install_addon(r".\borderify.zip", temporary=True)
driver.maximize_window()
driver.get("https://bot.sannysoft.com/")
time.sleep(10)
driver.quit()
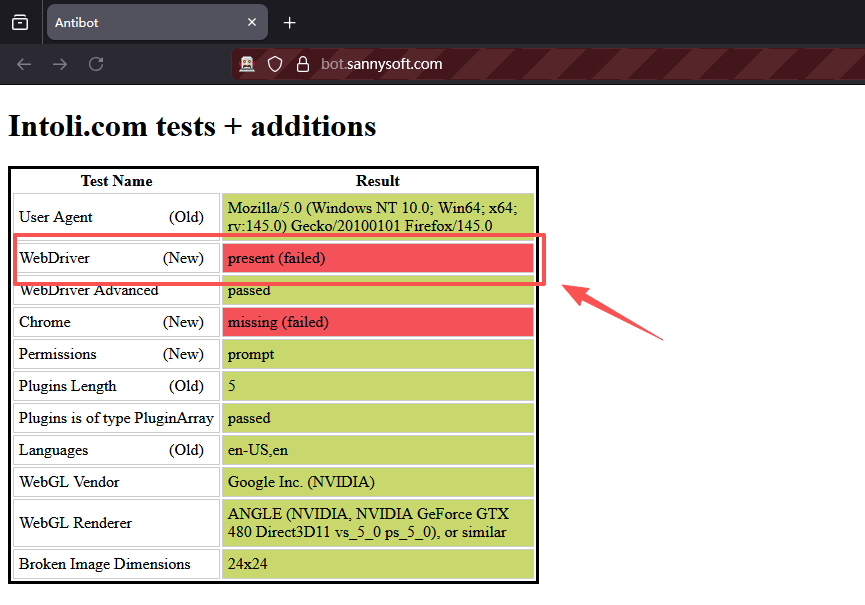
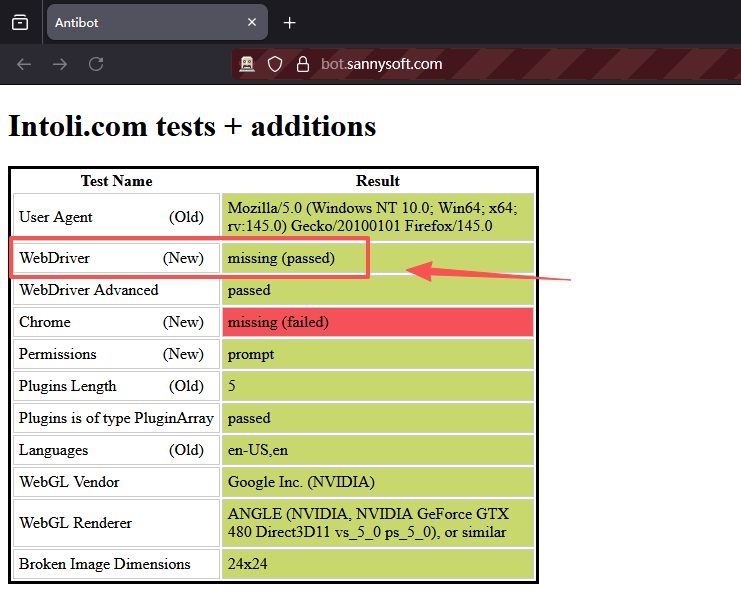
此时,访问 https://bot.sannysoft.com/ ,也成功实现伪装。
未记载扩展
加载了扩展
通过携带正常访问过的 Cookie 来绕过
上述的方法只能适用于某些限制不怎么严格的网站,对于某些有钱的网站,其可能会使用如 Cloudflare 等第三方工具采集更多的浏览器指纹来对自动化进行判断,此时,再用上面方法也未必有效。
这个时候,我们可以先使用正常的浏览器手动访问一遍,然后通过 F12 开发者工具,获取网站的 Cookie,然后在访问时携带正常访问的 Cookie 来跳过验证。
这个方法的很多时候都是有效的。不过请注意,通常这类 Cookie 具有 10-20 分钟的有效期限,在到期后,可能需要手动再获取一遍。
比如下述代码:
from selenium import webdriver
import time
service = webdriver.EdgeService(r"F:\Sdk\webdriver\msedgedriver.exe")
driver = webdriver.Edge(service=service)
cookie = {
"name": "name",
"value": "value"
}
driver.maximize_window()
driver.get("https://bot.sannysoft.com/")
driver.add_cookie(cookie)
driver.refresh()
time.sleep(10)
driver.quit()
对于 Cloudflare,验证通过后的会给 Cookie 写入一个名字为 cf_clearance 的键值对,携带这个键值对能在一段时间内免验证的通行网站。
当然,你也可以去寻找其他支持绕过 Cloudflare 的 python 库,比如:
cloudscraper。